In the previous Chapter we used the rlpp_designer to create a Pygame layout for our first reinforcement learning application. We encoded the actions the agent takes in our world, its rewards and penalties. This Chapter will focus on creating a representation of the agent's environment to help it navigate its surroundings. In some poetic manner of speech, we are giving eyes to our agent so they can see the world. We call an agent's surroundings the state of the agent.
Neural networks accept arrays of numbers as input, so we need to find a way to represent the state as a collection of numbers. We will resort to binary arrays to represent chains of conditions, having 0 as "No" and 1 as "Yes".
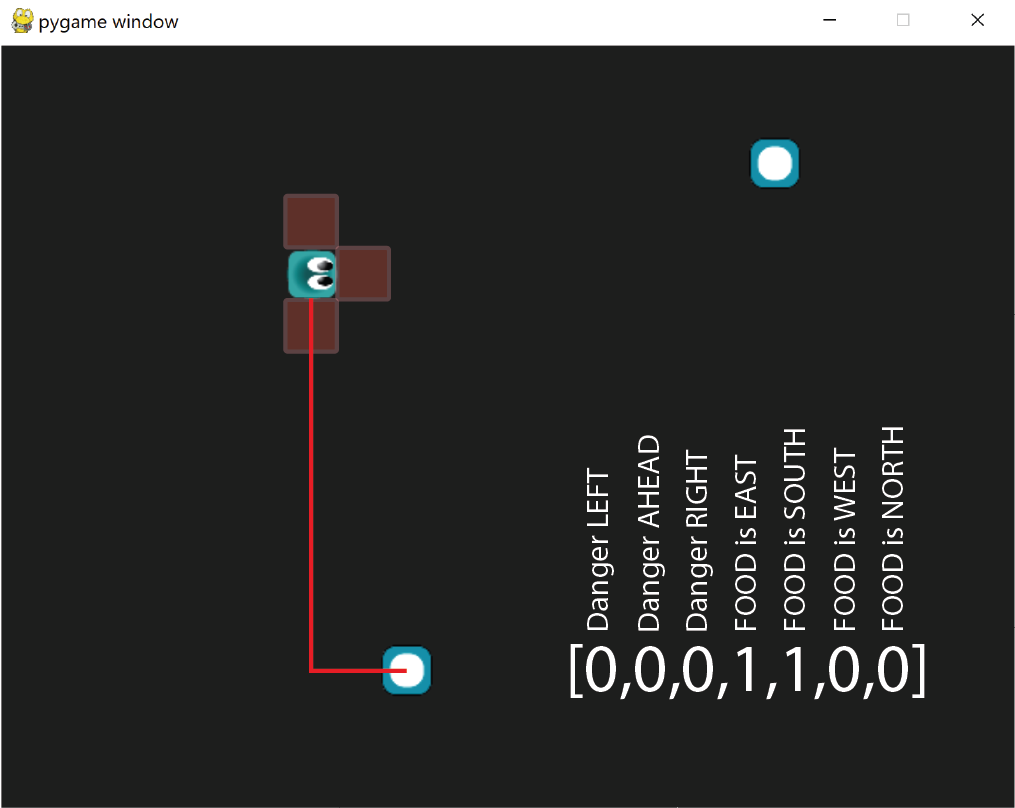
Although this may look like a one-hot-vector, it is not because there can be more than a single number 1. Our agent will be able to sense danger in its surroundings, and perceive where the closest food item is relative to the whole map. In the illustration above our agent will be able to see the immediate danger to its left, front and right directions represented by the red areas around the agent. If there is a wall in any of those areas we represent those positions with 1. For the food we first sort the food list to find the one item that is closest, then map that food item's position relative to the position of the agent. The food can be East, South, West or North to the agent. It sounds like we need two helper functions...
We begin by summoning two helper functions inside the get_state() method of the class Agent:
def get_state(self, foods):
dangers_around = self.get_dangers()
food_around = self.get_food(foods)
state = [0,0,0,0]
return np.array(state, dtype=float)
Notice the method self.get_food need a list of the food items, so we add the foods argument to the get_state() method. At this point, we can erase the default state variable that came with the template.
Evaluating dangers
Let's create the method get_dangers() inside our Agent class. Whether our agent is in a collision course against the wall depends on the combination of two parameters:
- The direction the agent is going
- Its position in the map

In this example, the position of the agent in the map is the same, but its current cardinal direction determines the type of danger that lies ahead. Let's map these cases in our function:
def get_dangers(self):
danger_vector = [0,0,0]
danger_EAST = int((self.x + SPEED) + (self.image.get_width()//2) >= SCREEN[0])
danger_SOUTH = int((self.y + SPEED) + (self.image.get_height()//2) >= SCREEN[1])
danger_WEST = int((self.x - SPEED) - (self.image.get_width()//2) <=0)
danger_NORTH = int((self.y - SPEED) - (self.image.get_height()//2) <= 0)
cardinal_dangers = [danger_EAST,danger_SOUTH,danger_WEST,danger_NORTH]
_idx = (self.index_cardinal_direction - 1)%4 #relative starting position of agent's left-ahead-right directions, based on its current direction
for i in range(3):
danger_vector[i] = cardinal_dangers[(_idx+i)%4]
return danger_vector
This is one of those functions that can give you nightmares at night, so let's dissect it bit by bit. First, remember how we represent the cardinal direction of the agent by using an index:
self.index_cardinal_direction is:
- EAST: 0
- SOUTH: 1
- WEST: 2
- NORTH: 3
- danger_EAST = int((self.x + SPEED) + (self.image.get_width()//2) >= SCREEN[0])
- danger_SOUTH = int((self.y + SPEED) + (self.image.get_height()//2) >= SCREEN[1])
- danger_WEST = int((self.x - SPEED) - (self.image.get_width()//2) <=0)
- danger_NORTH = int((self.y - SPEED) - (self.image.get_height()//2) <= 0)
We will place our questions into a list, arranged always in a clockwise direction and starting with EAST.
cardinal_dangers = [danger_EAST,danger_SOUTH,danger_WEST,danger_NORTH]
Now we can ask the agent in which direction it's currently going, to get a sense of which cardinal dangers to look at. For example:
- If the agent's cardinal direction index is 0 (EAST), we look NORTH(left), EAST(ahead), SOUTH(right).
_idx = (self.index_cardinal_direction - 1)%4
Then, our for loop will visit every entry in the danger_vector (three elements) while placing the value of its matching danger for the left, ahead, and right positions
Evaluating food proximity
To provide the agent with a sense of where the closes food item is (if any), we can create a new method get_food() in the Agent class:
def get_food(self,foods):
# identify which food is closest
candidate = None
shortest_distance = None
for food in foods:
if food is not None:
h = ((self.x + food.x)**2 + (self.y + food.y)**2)**0.5
if shortest_distance is None or shortest_distance>=h:
shortest_distance = h
candidate = food
# identify its position relative to the agent
if candidate is not None:
food_is_EAST = candidate.x >= self.x
food_is_SOUTH = candidate.y >= self.y
food_vector = [int(food_is_EAST),int(food_is_SOUTH),int(not food_is_EAST), int(not food_is_SOUTH)]
return food_vector
return [0,0,0,0]
The algorithm above can be divided in two main tasks. First, gather whichever food item is the closest to the player, based on the pytagorean distance h between the food and the agent. The best candidate will have the shortest distance to the agent.
Then, we create the list food_vector by asking if the food is to the east of the agent, and if the food is south of the agent. Each of these two questions has an inverse (WEST and NORTH), and we can safely asssume they are mutually exclusive scenarios. When the food is not east, then it has to be west. We represent this information in the food_vector by using the not operator, then casting the True/False boolean into a binary value 1/0.
What is left is merging the two vectors dangers_around and food_around into a single array with 7 elements.
def get_state(self, foods):
dangers_around = self.get_dangers()
food_around = self.get_food(foods)
state = dangers_around+food_around
return np.array(state, dtype=float)
We also need to remember to pass the foods list when we summon the method get_state from the Game Manager:
def update(self):
[pygame.quit() for event in pygame.event.get() if event.type == pygame.QUIT]
for agent in self.agents:
if not agent.isDead:
# get numerical interpretation of environment
previous_env = agent.get_state(self.foods)
# use model to predict a move
new_move = agent.get_action(previous_env)
# apply the move
reward, done, score = agent.play_step(new_move, self.foods)
# get new state from applied move
new_env = agent.get_state(self.foods)
# train short memory
agent.train_short_memory(previous_env, new_move, reward, new_env, done)
# add results to memory
agent.remember(previous_env, new_move, reward, new_env, done)
# if the game is out of agents, then game is over. Reset the game and train long memory
agents_alive = sum([1 for agent in self.agents if not agent.isDead])
if agents_alive == 0:
self.reset()
for agent in self.agents:
agent.n_games += 1
agent.train_long_memory()
And, finally, to inform the neural network its new input size is 7 for the state of our world.
SCREEN = (640,480)
MAX_MEMORY = 100_000
BATCH_SIZE = 1000
LR = 0.001
WORLD_STATES = 4
WORLD_STATES = 7
ACTION_STATES = 3
SPEED = 5